21深度 | 理想造芯往事:一场不跟风的赌局
 21世纪经济报道记者 易思琳
21世纪经济报道记者 易思琳
2026年北京车展媒体日当天,理想汽车董事长兼CEO李想组织了一场低调的老友饭局。
当天,李想与几位从理想出走,如今各自独立创业的高管们重聚餐桌。在场的有理想汽车前总裁沈亚楠、前智能驾驶预研负责人贾鹏、前智能驾驶量产研发负责人王佳佳、前第二产品线负责人张骁,还有前智能驾驶产品总监赵哲伦。
他们在不同时间离开理想,分别创立了赫宇机器人、至简动力、斜跃智能、维他动力。产品有专注于家庭场景的消费级机器人,也有专注于工业场景的机器人,还有团队专注于机器狗的研发。
饭桌间,他们调侃这是一场“车人狗聚会”。寒暄之外,几位创业高管向李想提出最多的诉求是:马赫M100能不能也向他们供应?

(车展聚会留影,图源:贾鹏朋友圈)
“外采其他家的芯片,从工具链、稳定性,再到效率、成本都不如马赫M100芯片。他们(指离职的高管)清楚我们自研芯片是什么水平。”李想在播客里说。
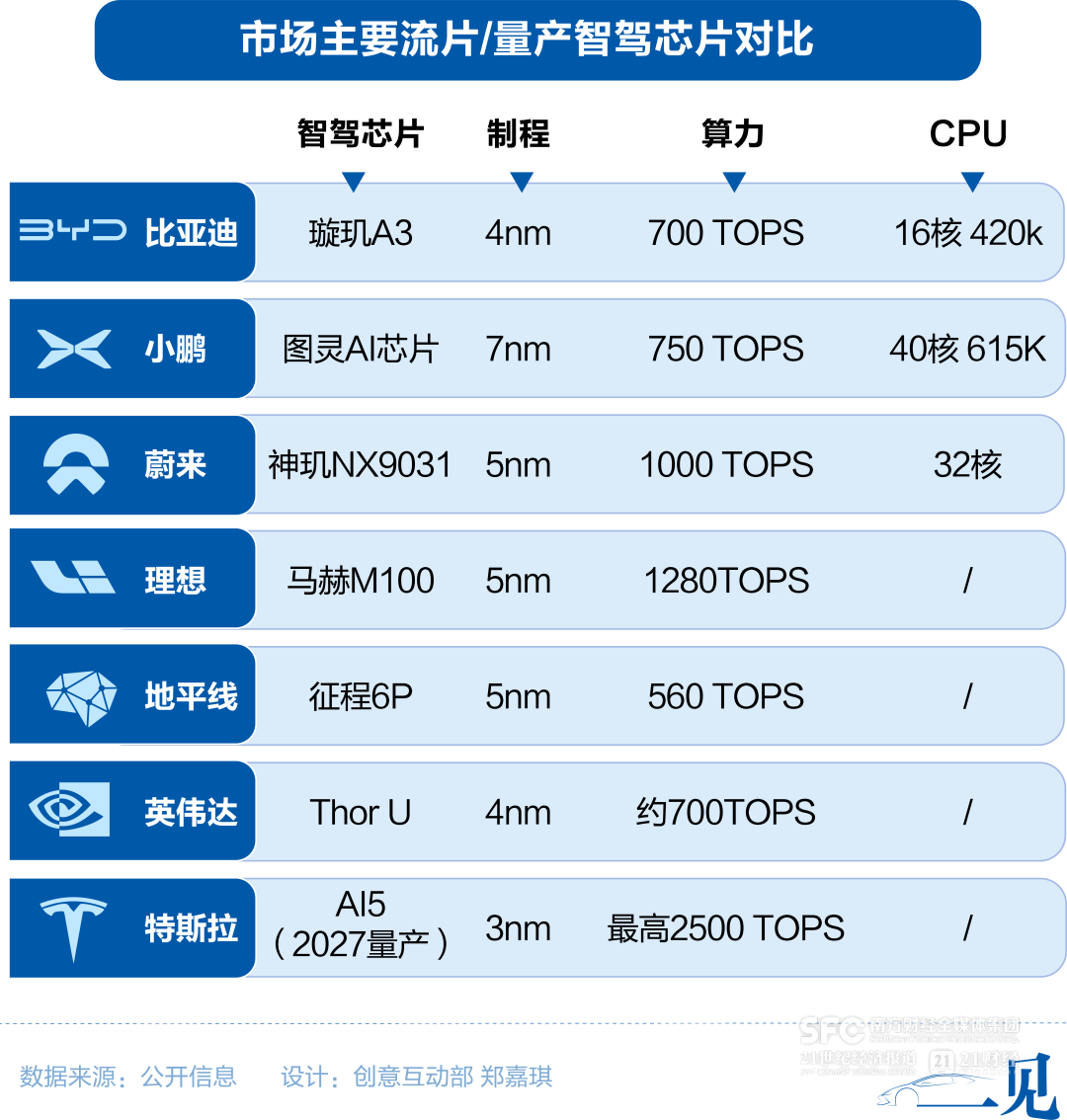
马赫100,单颗芯片算力达1280 TOPS,是当前新势力公司自研的芯片中算力最大的那一颗。对于行业来说,这颗芯片更为重要的意义在于:这是全球唯一一颗采用动态数据流架构的智能驾驶芯片。数据流架构不同于传统的冯·诺依曼架构,核心是数据驱动,并非指令驱动,能够减少缓存中的反复存取,释放更多有效算力,提高AI运行效率。
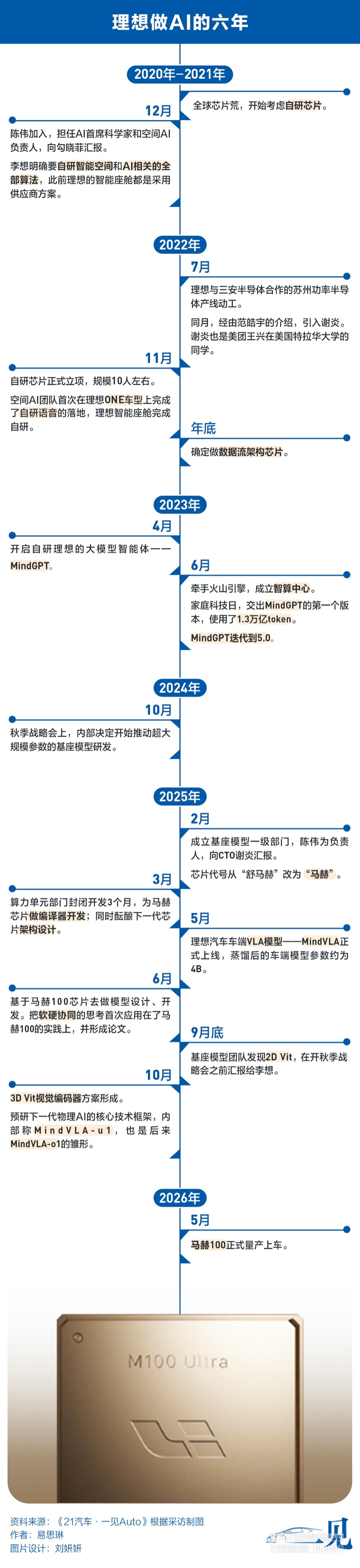
芯片是理想做AI的起点。自2022年开始,理想四年芯片攻坚,四年操作系统重构,三年大模型打磨。而对于智能汽车而言,芯片是心脏,操作系统是神经系统,基座模型是大脑,底盘是灵活的手脚。自此,理想的AI布局逐渐完善,搭建起一套具身智能体系。
李想曾在去年的AI Talk上表露野心:“理想既不是一家纯粹的造车公司,也不是一家纯粹的硬件公司,理想应该像苹果、华为一样,做一家人工智能的生态公司。”
All in AI,让理想站在了智能汽车行业最特殊的十字路口:一面是理想想要牢牢攥住、难以被复刻的下一个十年的未来底牌;另一面是重押底层技术带来的负重与不确定性。
在这场AI战略利弊博弈中,理想之所以敢下重注、走最难的全栈自研之路,所有的底气与抉择逻辑,或许都藏在过往数年步步为营的AI攻坚往事里。
芯片,AI底层体系的第一块拼图
理想自研芯片的想法萌生于2021年全球芯片荒。
彼时,原来1个月芯片交货周期被拉长到6个月、单颗芯片价格暴涨5~10倍,同时头部车企BBA还拿走了一半的芯片产能,留给理想等新势力车企的芯片供应并不多。
如果更换短缺的MCU芯片,操作系统和全新芯片的适配、验证周期一般需要六个月以上,这会带来上百亿元营收损失。供应链被卡脖子,让自研芯片被提上理想研发日程。
但在蔚小理三家中,理想是最晚启动芯片自研的公司。
早在2020年前后,蔚来从小米挖来“芯片老将”白剑,担任硬件VP,统筹智能驾驶芯片的研发;小鹏招揽特斯拉初代FSD芯片核心骨干谷俊丽,她也是小鹏初代图灵芯片架构总负责人,牵头搭建硅谷芯片团队。到了2022年,蔚来、小鹏自研芯片团队已经分别接近300人、200人,把自动驾驶AI芯片作为主攻方向。
而2021年,理想虽然已经开始考虑自研芯片,但并未付诸行动。上市和销量增长让公司缓过了劲,理想虽然手握百亿现金流,但在选择做什么不做什么、怎么做时,依然希望把钱花在刀刃上。
和蔚来、小鹏不同,理想认为,功率半导体才是理想认定的“刀刃”,战略优先级高于自动驾驶芯片。在当时,自动驾驶芯片仅影响智驾体验,且供给渠道多元;而功率半导体是电驱系统的根基,供给高度集中,一旦断供可能导致整车停产。2022年7月,理想与三安半导体合资动工建设苏州功率半导体产线。
功率半导体是生存底线,但自研AI芯片才能抢占智能化的代差优势。2022年7月,理想汽车从华为引入谢炎,芯片、操作系统等都归在谢炎主管的系统与计算群组之下,芯片团队才正式组建。
谢炎刚加入时,理想芯片团队只有两名员工,不到一个月就剩一个人了。剩下的那名员工问谢炎:“公司已经决定做芯片,但要怎么做?资源有限,是不是要先做小芯片试水?”小芯片是指低成本、低算力的AI芯片,用于试错、验证基础能力。
但即使在早期团队规模不大、公司投入谨慎的情况下,谢炎也反对做小芯片试水。谢炎认为,一开始,自研的战略目标必须正确。

“我和李想有一个非常一致的意见:自研不是为了证明自己有能力做,而是得真正解决问题。”谢炎在群访现场告诉《21汽车·一见Auto》。当时汽车智能化虽然还没发展到现在的大模型阶段,但团队知道未来车内需要的AI算力只会越来越高,需求推动下,外购高端芯片的成本也会变得越来越高。容易做的小芯片只能应付当下,无法匹配长期智能化的算力需求。
2022年11月,自研芯片项目正式在理想内部立项,团队规模10人左右。
谢炎回顾芯片立项说:“供应商要满足所有的客户,不可能只给一个客户提供,这就意味着他们很难满足非常极致的定制化需求。”
行业里最强大的汽车芯片供应商是英伟达,当时量产车上普遍搭载英伟达的Orin芯片,而算力更大的Thor芯片也已经处于研发设计中。“如果自研做不到比外购芯片更好,那做的意义不大。”谢炎告诉《21汽车·一见Auto》。
扔掉架构依赖,不当第二个英伟达
经过半年时间分析,团队给芯片自研设定的目标是:一半成本、两倍性能,也就是四倍效能。
但谢炎清楚,要在一半的成本下做得比英伟达更好,采用英伟达的技术路线行不通。
按照既定路径做研发,只会成为第二个英伟达,并不能超越它。对当时的芯片团队来说,只能扔掉既定架构依赖,回到本质,从第一性原理看AI计算本身还有什么机会。
“英伟达比你早启动几十年,积累比你深,资源比你多几个数量级。就像你跟博尔特在100米赛道上,他比你早跑2秒,你不可能超过。”谢炎补充道。
最终理想选择动态数据流架构。
这一架构同传统的冯·诺依曼架构的区别在于:传统CPU/GPU芯片采用的是指令驱动,按照“先取指令,再取数据,再执行”的逻辑;而数据流架构则是数据到齐之后就立刻执行,执行完直接传递给下一个单元,数据自己决定什么时候计算,不用 CPU/GPU 指挥。这样一来,相比传统GPU架构,数据流架构能够减少缓存中的反复存取,释放更多有效算力,提高AI的运行效率。
数据流架构并非新兴概念。早在上世纪60年代,这套计算思想便已提出,谢炎就读美国特拉华大学硕士期间的导师高光荣教授,正是数据流架构方向的奠基人之一。但它在过去数十年的通用计算时代并未成功:中国几乎没有大规模商业化项目;美国有Groq、Cerebras等公司,但均面向数据中心云端推理,不落地车载场景。
不管是2022年,还是2026年,选择动态数据流架构设计自动驾驶芯片的车企都只有理想一个。

行业普遍回避数据流架构,核心顾虑有三:首先,生态要从零搭建,软件重构成本极高。传统CPU/GPU历经数十年发展,拥有成熟工具链,其编译库、算子库、海量开源算法模型等全部基于指令驱动控制流开发;而数据流架构无任何兼容基础,需要从零全套自研编译器、调度器、模型映射工具链,不存在成熟第三方工具可复用。
其次,通用适配能力薄弱。架构仅擅长规整、标准化AI运算,应对车载多变、复杂的实时路况场景容错性不足。
最后,芯片研发周期长,且投入量大,如果研发方向不对,理想这几年在芯片上投入的近10亿元都将成为泡沫。
为什么在全行业观望之时,理想敢押注小众架构?据谢炎介绍,核心在于理想团队跳出了芯片迭代的惯性思维,从AI计算的第一性原理出发,重构底层逻辑。
在验证数据流架构路线是否可行时,团队发现这一思想的本质是:传统计算依赖于人类编程的“翻译”中介,这降低了效率,即所有的计算行为都要服从指令调度,天然造成了数据搬运冗余、算力空转等问题。如果回到计算本质,可以把中间的“翻译”拿掉,让数据自主驱动计算,构建一套基于数据流的架构。
“过去数据流架构没发展起来的原因是计算规模、数据规模不够大。”谢炎进一步解释称,当计算规模、数据规模大到一定程度时,会发现冯·诺依曼架构是控制流、集中式的,不是不能扩展,但扩展的额外代价更高、效率更低。所以车企可以设计专门针对单一形态的、全新的计算架构,理想一直在坚持走这条路。
“我们采用动态数据流架构没有赌的成分,团队手敲了140万字的资料来验证这件事的可行性。”李想在L9 Livis发布会上表示。
理想芯片在2022年11月正式立项,于2024年流片。最初这款芯片的名字叫“舒马赫”,2025年改名为“马赫”。“因为马赫是速度计量单位,代表速度快。我们做的是芯片,希望AI计算速度更快。”一位理想芯片团队人士对《21汽车·一见Auto》解释称。
三个月封闭开发,死磕编译器
全新架构芯片落地,普遍面临一个行业共性难题:硬件定型后,缺乏适配的软件工具链。而其他的芯片供应商都会针对自家硬件,推出对应的推理加速框架以最大化利用芯片性能,比如英特尔有OpenVINO,ARM有ARM NN,英伟达有TensorRT等,专属软件工具链已经成为高端芯片量产落地的标配。
想让更多软件算法人员采用这款芯片的同时,不变更自己常用的开发工具,同时最大化挖掘数据流架构的极致算力,需要设置一套“媒介”“通用接口”——这便是编译器。它是衔接硬件与算法的核心桥梁,能将程序员常用的编程语言转换成芯片可识别、可执行的机器语言去执行。程序员可以用自己熟悉的编程语言直接编写代码,在该芯片上运行程序,能有效提高基于该芯片的开发效率。
“编译器要做的事是给芯片做一套快速的适配接口,以快速地把后续的新算法部署在芯片上。”一位芯片行业人士向《21汽车·一见Auto》解释。
一位芯片行业的人士补充,一款芯片的开发周期是3~5年,发展本身就滞后于算法。芯片流片成功之后,“新算法要跑在老芯片上,就得让芯片不停地适应新算法。编译器开发成功之后,就能缩短开发周期、提高开发效率。”
2025年,马赫芯片回片验证。那一年,芯片团队的工作重心,也从硬件调试转向为新的芯片开发编译器,同时做好芯片的改版和迭代,为量产上车做足准备。《21汽车·一见Auto》独家获悉,2025年3月,理想汽车召集算力单元部门进行了为期3个月的封闭开发,核心就是为了马赫芯片做编译器开发。
编译器研发的高门槛,首先源于硬件适配的复杂性。芯片架构复杂,包含大量的晶体管和复杂的技术单元,编译器需要对这些硬件特性进行优化;编译器也需要和芯片架构进行深度协同,例如编译器需要理解该芯片的流水线结构、缓存设计、指令集扩展等特性。
“还难在生态上。”一位业内人士表示。传统的CPU编译器经过几十年发展,已经有一套成熟的理论,比如英伟达的上层架构、谷歌的架构已经非常成熟,后来者只要在此基础上做差异化即可。而数据流架构与传统芯片架构逻辑完全不同,没有现成的编译生态可以复用。举个例子,当前程序员最常用的开发工具是Python,如果现在一款新的芯片无法兼容主流开发工具,会大大降低程序员对该芯片的使用效率。
谢炎告诉《21汽车·一见Auto》,马赫芯片从设计之初就在做编译器的开发工作,流片前已经跑通了很多模型。而去年为期3个月的封闭开发,是想持续迭代版本,把芯片的效率和性能充分发挥出来。
最终马赫100单颗芯片算力达到1280 TOPS。“你不会知道最佳性能点到底在哪,只能不断逼近。‘跑通’跟‘跑到最好’距离非常大。当时我们用马赫芯片跑VLA模型时,性能已经是ThorU的三倍了,但我们觉得依然有潜力可挖。”谢炎说。
如何把大语言模型塞进芯片?
2025年上半年,在芯片团队封闭开发做编译器时,基座模型团队也启动了重要工作——把大语言模型塞进马赫100芯片里,以充分发挥芯片的可用算力、提升本地模型的能力。
此前,基座模型团队在重新定义Thor U芯片上的VLA智驾模型时,发现了行业痛点:即便搭载行业第一梯队的车载芯片,大语言模型实际运行性能依旧大幅缩水。
这一问题根源,来自行业长期割裂的研发模式:过去,芯片工程师埋头追求更高的峰值算力,算法工程师则疯狂堆叠模型参数,两者在各自的轨道上狂奔。结果就是:软件与硬件在最后集成阶段才仓促碰面,彼此妥协、相互迁就,大量算力被闲置,大量功耗被浪费。
这种软硬分离的研发方式在对算力需求呈指数级攀升的今天,正变得难以为继。
过去云端大模型只是关注参数量、训练数据,完全不考虑芯片带宽、算力限制、功耗等硬件约束。 “之前总是想着模型参数量越大,把部署在车端的硬件算力提高即可。但后来发现这条路行不通。”一位参与了模型研发的理想汽车芯片工程师回忆称,如果继续沿着过去“堆料”的老路走下去,永远只能跟在别人身后吃灰。
团队最终意识到,真正的解法不在芯片厂商的下一代产品路线图里,而在底层研发逻辑的重构之中:如果要把云端的超大模型塞进芯片里,需要在模型设计之初就把硬件能力考虑进来,这样才能让芯片资源发挥到最大的效能。
“先算硬件瓶颈,再设计模型。”上述人士总结。
最后,他们提出了一套可量化、可预测的软硬协同数学框架,即今年3月理想汽车联合国创决策智能技术研究所发布的“软硬协同设计定律”。

(基座模型团队的研究成果,Hardware Co-Design Scaling Laws via Roofline Modelling for On-Device LLMs,图源:Google搜索)
该定律搭建起统一数学逻辑,把芯片的物理特性和算法的计算需求同时“翻译”成数学语言:只需要输入芯片硬件参数、模型性能目标,公式便能自动输出最优的软硬配比方案。这相当于为协同设计建立了“通解公式”。
依托这套框架,团队得出的核心结论是:没有适配全场景的通用芯片,只有场景最优芯片。硬件架构的最优解高度绑定上层算法需求,这从根本上证明了“算法定义芯片”的必要性——只有深度吃透上层算法的真实需求,才能设计出最高效的专用计算芯片架构。
谢炎说,选择数据流架构并不是最重要的。对这块芯片的研发助力最大的还是联合设计,芯片设计前期更重要的是理解透彻模型端的需求。
“选对架构,并不会让芯片研发的速度变快。”谢炎表示。团队都非常赞同的一点是:芯片并非芯片团队孤立设计,而是跟模型团队、自动驾驶团队一起设计。
“没有他们的输入与认知,没有大家一起坐下来分析,就会做偏,而做偏就会带来时间的浪费。”谢炎补充道,“这种类似的协同度,我在其他公司没有看到过,我以前工作的任何一家公司没有看到过这种高密度、跨部门的协同。”
“决策大脑”,同步进化
在把大语言模型塞进马赫芯片前,基座模型团队的主要工作是搭建车载原生通用大模型底座VLA——这是塑造理想AI的“决策大脑”。
在基座模型团队参与进来之前,理想智能驾驶团队的VLA基于外部的开源模型,这会导致智驾、座舱的AI体验相互割裂。2025年春节过后,李想认为,未来理想的VLA一定要用自研的基座,可以打通视觉感知、语言理解、车辆动作决策,实现座舱交互、高阶智驾、车身控制共用一套认知体系,就让基座模型团队和自动驾驶团队一起做了联合开发,重新定义车端的VLA模型。
同年5月,理想正式发布重新定义后的车端VLA模型——MindVLA,理想团队称该模型参数大约为4B(40亿),由云端训练的基座模型蒸馏而来。
把自研的VLA框架完成体系定型后,基座模型团队下半年就很少参与智能驾驶的常规工作了,而是将重心转向基于物理AI的VLA框架的前瞻性预研。
“基座模型不需要跟自动驾驶卷同一代的技术,应该卷下一代的技术趋势。”原理想汽车基座模型团队负责人陈伟曾向我们回忆道。当时基座模型团队200人,有很多个项目要承接,最终,他们抽调3—4名核心人员,组建小型专项组,启动下一代VLA研发架构的开发。
下一代VLA架构,应该怎么搭?一开始,团队并没有思路。后来他们从已经推送的VLA版本的真实场景痛点亟待提升之处寻找突破点。MindVLA上线后,曾有车主反馈,白天和晚上VLA表现不一致,会出现无诱因异常减速、动力响应滞后、提速乏力等问题。
团队复盘后认为,这一问题的根源,在于传统视觉编码器的感知缺陷:模型仅能识别画面中的物体类别,无法精准获取障碍物的空间深度、距离参数,最终导致空间位置误判,引发车辆决策异常。在VLA模型里,视觉编码器是三大核心组件之一,核心作用是把摄像头捕捉到的画面转换成机器可学习、可理解的高维抽象特征,是车辆视觉感知、场景理解、决策输出的底层基础。
因此,团队决定开始把技术攻坚的核心转向视觉编码器的突破上。
行业内主流量产的VLA模型,均采用SigLip(谷歌2023年推出的图文多模态预训练视觉编码器)作为通用视觉编码器。但该方案存在天然短板。“无论是推理的效率,还是最终的编码效果,都不太适配高阶智驾的需求。”一位深度参与下一代VLA研发的工程师告诉我们。
上述人士解释称,SigLip是2D平面感知模型,更关心“这是什么”,就像一个高度近视且记忆力超群的人,能一眼认出面前站着的是一个人,但看不清这个人到底长什么样,也判断不准他离自己有多远。“车去执行指令的时候,只知道某处有物体,却不清楚该物体是否会造成碰撞。如果能让模型学会判断距离,就能通过距离的远近去采取相应避让策略。”上述人士解释道。
与此同时,传统的BEV方法同样存在局限,会将场景拍平为俯视图,这迫使模型只能关注高度维度上最显著的单个目标。团队认为,如果能在视觉表征上加入深度信息,让模型对空间位置、空间深度有准确理解,把物理世界用立体的维度表征出来,也许就可以解决这个问题。

(BEV感知示意图)
硬件传感器方面,在过去理想的智驾模型里,激光雷达一直都作为前融合的主要传感器。和摄像头相比,激光雷达能生成密集的三维点云,还原物体的轮廓、体积和复杂结构,也能区分行人、骑行者、车辆等细小障碍物。
但激光雷达也有限制。另一位参与了模型开发的工程师告诉我们,激光雷达最多看80米,探测距离有限。同时,激光雷达采集的点云数据很多、采集效率比较低、延时也比较长,“这就意味着,如果每一次VLA都需要使用激光雷达的点云数据,VLA的响应就会变慢。”
为突破硬件与传统算法的双重限制,团队商议出全新的研发思路:或许可以直接用RGB纯视觉摄像头(通过红R、绿G、蓝B三原色通道采集环境反射光,输出彩色二维画面)去采集数据,摄像头对空间位置、空间深度都能有准确的理解。
他们开始面向2D图像而非点云数据构建了一套视觉编码器,发现可以用比SigLip更小的模型尺寸实现更好的呈现效果、更快的推理速度。他们给这套视觉编码器取名叫2D ViT(二维视觉Transformer,只能看懂平面照片,没有深度、空间距离概念)。
这套预研设计落地后,陈伟随即汇报给了李想。国庆假期后,理想的秋季战略会召开,据一位参会人士称,李想在月底的秋季战略会上“大谈特谈”基座模型团队做的这套方案。
不过,研发团队很快发现,2D ViT呈现的依然是点,而不是三维空间。团队在想是否可以把2D图像变成一个有着X、Y、Z的空间三维坐标系,这样就能看得更清楚。最后,这套视觉编码方案就从2D ViT发展成为了能表征空间深度的3D ViT(三维视觉Transformer)。
“我们测试过,用单目RGB摄像头和激光雷达同时探测,在空间感知精度上,纯视觉保持了激光雷达95%精度。而且它能很好地弥补激光雷达探测距离不远的缺点。”理想基座模型的工程师说。
他表示,3D ViT立体视觉编码技术的价值并不仅仅在于对智能驾驶的赋能上,还能够充分应用到机器人的研发中。“空间距离判断,在机器人同物理世界的交互中非常重要。”
不过,有了3D ViT之后并不意味着理想就抛弃了激光雷达。“我们会走一条激光雷达与视觉的融合之路。”谢炎明确表示。
今年1月接手基座模型团队的詹锟表示,激光雷达不再适合作为前融合主传感器,其存在探测距离有限、延迟较高、帧率上限仅15Hz等物理短板,更高帧率感知只能依靠纯视觉,纯视觉后续会成为主力感知方案。但激光雷达仍具备安全兜底价值,可保障L3、L4高阶智驾极端场景安全。

(詹锟,图片来源:理想汽车官方)
詹锟说,理想汽车下半年最重要的两件事:第一,用纯视觉提高帧率,把芯片性能发挥到更大,反应速度大幅提升;第二,激光雷达会承担很重要的数据采集环节。
“想要催生颠覆性创新,得先打破原来的边界,而不是follow别人的路线。”这是谢炎在理想科技日群访上说的一句话。
这句话也能概括理想从成立以来多数的决策逻辑:行业扎堆做纯电时,理想选择了并不被看好的增程;各家内卷动力、性能时,理想另辟蹊径,首创“冰箱彩电大沙发”,选择在产品定义上创新。
All in AI后,理想也如此。自研芯片上,一众车企跟随英伟达路线,只有理想在自研芯片上选择动态数据流架构;行业争相复刻端到端+VLA方案,理想切换重心,攻坚VLA基座。
每一步抉择,在当时皆是市场眼中的非共识,但待理想成功后,又迅速成为行业模仿、追随的范本。
这些非共识选择的本质都是在“赌”:赌自己找到一条细分赛道,赌自己能跑通。赌对了,是独一份的先发优势与长期增长的底气;赌错了,是无人兜底的试错代价与短期市场阵痛,且如果再想重新打牌,难度就大了。
但无论对错,理想都要承担起选择的重量。
(作者:易思琳 编辑:吴晓宇,张明艳)
南方财经全媒体集团及其客户端所刊载内容的知识产权均属其旗下媒体。未经书面授权,任何人不得以任何方式使用。详情或获取授权信息请点击此处。

